概述
节点维度监控图表聚焦于单台主机或虚拟机的运行状态,深入监控CPU、内存、磁盘、网络等基础资源使用情况,并结合节点上的容器实例、系统事件与告警信息,实现对节点性能瓶颈、异常行为与故障风险的精细化洞察,保障节点层面的稳定性与可靠性。
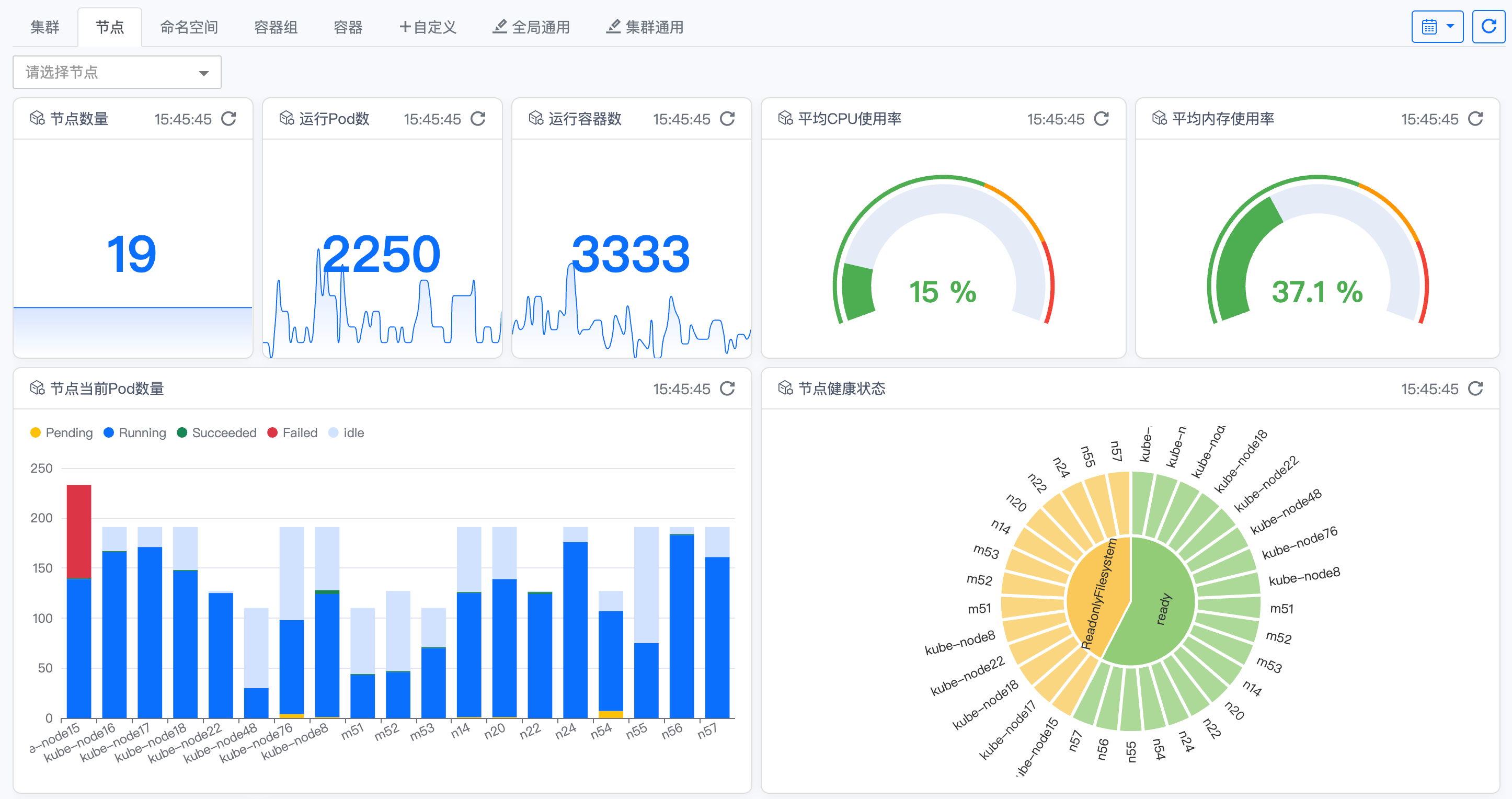
核心监控指标说明
1. 节点数量
- 含义:当前 Kubernetes 集群中所有节点的总数。
- 监控逻辑:实时统计集群内节点的存活数量,反映集群的节点规模。
- 异常场景:节点数量骤减(如因宕机、网络故障导致节点离线)时触发告警。
2. 运行Pod数
- 含义:所有节点上当前处于运行状态的 Pod 总数量。
- 监控逻辑:统计集群内所有节点上的 Pod 运行总量,反映集群的业务负载规模。
- 异常场景:Pod 数量异常波动(如骤增导致资源耗尽,或骤减导致服务不可用)时触发告警。
3. 运行容器数
- 含义:所有节点上当前运行的容器总数量(每个 Pod 可包含多个容器)。
- 监控逻辑:统计容器的运行总量,间接反映集群的业务组件规模。
4. 平均CPU使用率
- 含义:所有节点的 CPU 使用率平均值,反映集群节点的 CPU 资源消耗程度。
- 指标范围:0%
100%,绿色区间(0%70%)为正常,黄色(70%~90%)为警告,红色(≥90%)为严重告警。
5. 平均内存使用率
- 含义:所有节点的内存使用率平均值,反映集群节点的内存资源消耗程度。
- 指标范围:0%
100%,绿色区间(0%80%)为正常,黄色(80%~95%)为警告,红色(≥95%)为严重告警。
6. 节点当前Pod数量(按状态分布)
- 状态说明:
- Pending(黄色):Pod 处于等待调度状态,可能因资源不足、节点亲和性等原因导致。
- Running(蓝色):Pod 正常运行中。
- Succeeded(绿色):Pod 执行完成并成功退出(如一次性任务)。
- Failed(红色):Pod 执行失败,容器异常退出。
- Idle(浅灰色):Pod 无实际业务负载,处于空闲状态。
- 监控逻辑:按节点统计 Pod 状态分布,重点关注
Failed状态的 Pod 占比。
7. 节点健康状态
- 状态说明:
- ready(绿色):节点正常,可调度 Pod。
- Readonly filesystem(黄色):节点文件系统只读,可能因磁盘故障导致。
- 其他异常状态:如节点未就绪(NotReady),可能因网络、组件故障导致。
- 监控逻辑:统计各状态的节点数量占比,反映集群节点的整体健康度。
CPU内存相关
CPU和内存是系统运行的核心资源,直接影响服务性能和稳定性。本部分监控指标帮助您实时掌握处理器负载情况和内存使用状况,及时发现性能瓶颈和资源不足问题,确保系统高效稳定运行。
通过图表可清晰查看CPU使用率、负载趋势以及内存占用分布,为容量规划和性能优化提供数据支撑。

磁盘相关
磁盘存储着系统核心数据和应用文件,其空间和性能直接关系到业务连续性和数据安全。本部分提供磁盘容量使用率和I/O性能双重监控,帮助您及时预警存储空间不足风险,并评估磁盘读写能力。
通过多维度图表展示,您可以全面了解存储资源消耗模式,制定合理的清理策略和扩容计划,保障数据存储的可靠性与高效性。


网络相关
网络是系统对外服务的通信命脉,直接影响用户体验和业务可达性。本部分监控网络带宽使用、连接状态和流量趋势,帮助您掌握系统的网络负载情况和通信质量。
通过可视化图表,您可以快速识别网络拥塞、异常连接或带宽不足等问题,为网络优化、带宽调整和故障排查提供关键依据。

作者:叶奕珺 创建时间:2025-11-03 17:23
最后编辑:叶奕珺 更新时间:2026-01-15 14:15
最后编辑:叶奕珺 更新时间:2026-01-15 14:15
