概述
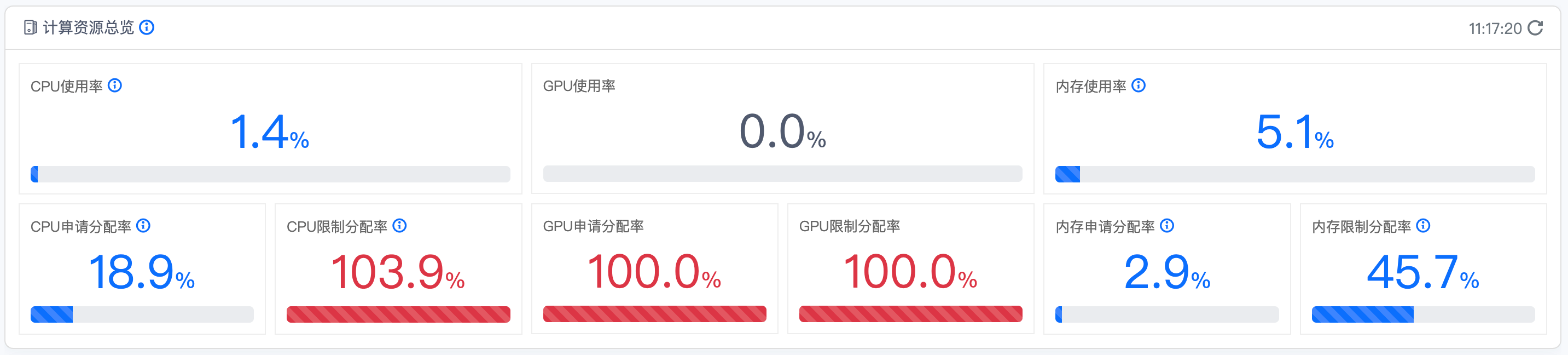
本图表展示了 Kubernetes 集群中关键计算资源的实时使用情况和分配状态,帮助运维人员快速了解集群资源状况。

GPU的场合显示如下:
监控指标说明
CPU 相关指标
1. CPU使用率
- 指标含义:当前集群所有节点上,CPU实际使用量占总物理 CPU 容量的百分比。
- 技术解析:
- 该指标通过
node_cpu_seconds_total等Prometheus指标计算得出。 - 反映实时负载而非预留资源。
- 该指标通过
2. CPU申请分配率
- 指标含义:当前集群所有容器 CPU申请
requests.cpu总和占集群总 CPU 核数的百分比。 - 技术解析:
- requests是K8s调度依据,确保Pod有足够资源运行。
- 调度器根据节点剩余可分配CPU(allocatable)进行调度决策。
- 接近 100% 时,新 Pod 可能因资源不足而无法调度。
3. CPU限制分配率
- 指标含义:当前集群所有容器 CPU限制
limits.cpu总和占集群总CPU核数的百分比。 - 技术解析:
limits.cpu是容器能使用的CPU上限。- K8s 允许
limits.cpu总和超过物理容量,依靠系统调度实现超卖。 - 基于CPU是可压缩资源的特性,通过时间片轮转实现共享。
内存相关指标
1. 内存使用率
- 指标含义:当前集群所有节点上,实际使用的内存占可用总内存的百分比。
- 技术解析:
- 通过
node_memory_MemTotal_bytes和node_memory_MemAvailable_bytes指标计算得出。 - 反映实时内存消耗情况。
- 通过
2. 内存申请分配率
- 指标含义:当前集群所有容器 内存申请
requests.memory总和占集群总内存的百分比。 - 技术解析:
- 内存request是硬性保证,节点会为此预留内存。
- 直接影响Pod调度,节点必须有足够空闲内存才能调度Pod。
- 与CPU不同,内存是不可压缩资源,OOM会导致容器终止。
3. 内存限制分配率
- 指标含义:当前集群所有容器 内存限制
limits.memory总和占集群总内存的百分比。 - 技术解析:
limits.memory是容器能使用的内存上限。- 超出
limit.memory会导致容器被OOM Killer终止。
GPU 相关指标
1. GPU使用率
- 指标含义:当前集群中 GPU 设备的实际使用率
- 技术解析:
- 通常通过 NVIDIA DCGM 或直接读取GPU驱动指标获取。
- 指标路径:
DCGM_FI_DEV_GPU_UTIL。 - 反映SM(流多处理器)计算核心的活跃百分比。
2. GPU申请分配率
- 指标含义:当前集群所有容器 GPU申请
requests.nvidia.com/gpu总和占集群总GPU核数的百分比。 - 技术解析:
- 在K8s中通过
nvidia.com/gpu资源类型申请。 - 调度器确保节点有足够GPU资源才能调度Pod。
- 申请单位通常是整张GPU卡,部分支持分片(MIG)。
- 在K8s中通过
3. GPU限制分配率
- 指标含义:当前集群所有容器 GPU限制
limits.nvidia.com/gpu总和 占 集群总GPU核数的比例。 - 技术解析:
- GPU限制通常与申请值相同,因为GPU通常不超卖。
- 特殊情况:使用GPU虚拟化或时分复用技术时可能有超卖。
- 通过设备插件(device plugin)和kubelet配合实现资源隔离。
计算资源总览展示了当前集群中CPU和内存的使用率

GPU的场合显示如下:

作者:叶奕珺 创建时间:2024-07-25 22:51
最后编辑:叶奕珺 更新时间:2026-01-15 14:15
最后编辑:叶奕珺 更新时间:2026-01-15 14:15
