概述
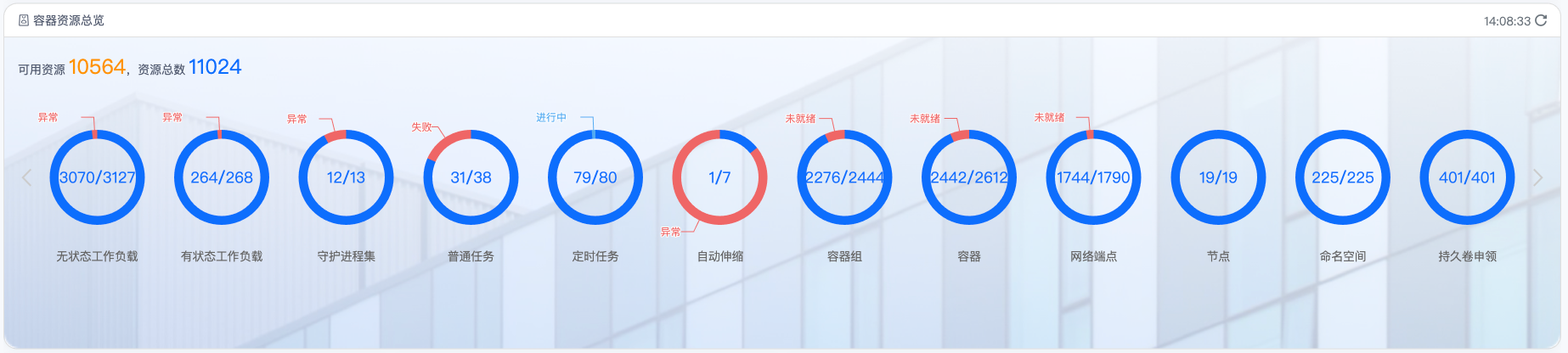
本图表集中展示 Kubernetes 集群各类核心资源的使用状态与健康状况,为运维人员提供集群运行状况的全局视图。

主要功能
1. 可视化健康状态展示
- 环形图可视化:每个核心资源类型均以环形图形式直观展示正常与异常比例
- 颜色编码:
- 蓝色区域:代表正常健康的资源
- 红色区域:代表存在异常的资源
- 区域大小比例反映异常资源占比
2. 实时状态信息查询
- 正常资源统计:实时显示各类资源的健康数量
- 异常资源明细:详细列出存在问题的具体资源实例
- 状态动态更新:所有数据实时同步集群状态变化
3. 快速导航与排查
- 一键直达详情:直接从异常列表跳转到具体资源管理页面
- 上下文关联:保持导航上下文,便于深入分析
交互操作
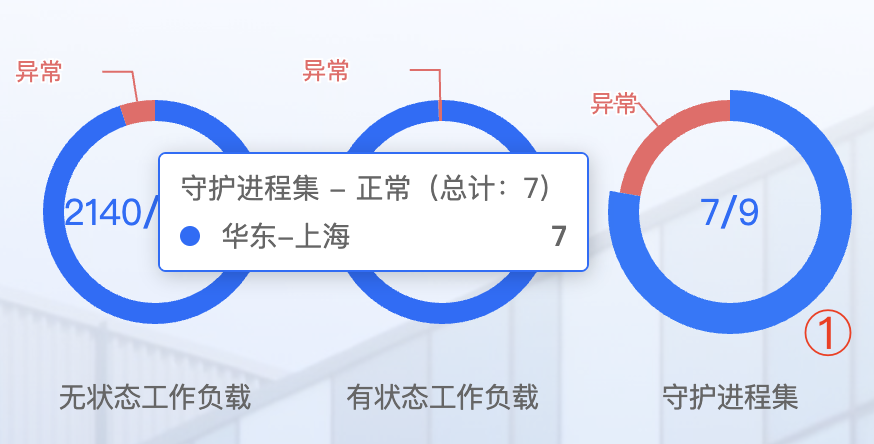
1. 查看正常资源统计
操作步骤:
- 将鼠标悬停在环形图的蓝色区域
- 系统将显示提示框,展示:
- 该资源类型的正常数量
- 资源总数
- 正常率百分比
使用场景示例:
- 快速确认集群中健康节点的数量
- 查看已成功部署的Deployment比例
- 监控Pod就绪率变化趋势
2. 查看异常资源详情

操作步骤:
- 将鼠标悬停在环形图的红色区域
- 系统将展开异常资源列表,显示:
- 异常资源名称/标识
- 所属命名空间
- 异常状态简述
- 异常持续时间(如可获取)
使用场景示例:
- 发现具体哪个Deployment部署失败
- 定位未就绪的Pod及其命名空间
- 查看存储卷申领的异常状态
3. 跳转至异常详情页面
操作步骤:
- 在异常资源列表中,点击任意异常条目后的”查看详情”链接
- 系统将跳转到该资源的详细管理页面
使用场景示例:
- 深入分析Pod未就绪的具体原因
- 查看Deployment滚动更新的详细状态
- 处理持久卷申领绑定问题
资源状态说明
1. 节点 (Node)
- 正常状态:节点监控组件正常运行,能够正常采集指标数据
- 异常状态:节点监控组件无法正常工作,无法采集该节点的指标数据
2. 命名空间 (Namespace)
- 正常状态:命名空间处于
Active活跃状态 - 终止中状态:命名空间处于
Terminating终止中状态
3. 无状态工作负载 (Deployment)
- 异常状态:Deployment的状态条件中存在非”true”状态的条件,表示部署配置或运行状态存在问题
详细说明:
当Deployment的状态条件中存在非”true”的值时,表示该Deployment在部署或运行过程中遇到了问题。Deployment通常有以下几种状态条件需要监控:
Available(可用性)条件
- 当此条件为false时,表示Deployment没有达到期望的最小可用副本数
- 可能原因:镜像拉取失败、资源配额不足、节点调度失败、健康检查未通过等
Progressing(进行中)条件
- 当此条件为false时,表示Deployment的滚动更新进度停滞
- 可能原因:新版本Pod启动失败、旧版本Pod终止失败、就绪检查超时等
ReplicaFailure(副本失败)条件
- 当此条件为true时,表示创建或删除Pod副本时遇到了错误
- 可能原因:节点资源不足、存储卷挂载失败、网络策略限制等
这些条件的异常通常意味着:
- 新版本应用部署失败,需要检查镜像、配置或资源限制
- 滚动更新被阻塞,可能因为新Pod无法达到就绪状态
- Deployment无法维持期望的副本数,可能存在资源竞争或节点问题
4. 有状态工作负载 (StatefulSet)
- 异常状态:StatefulSet的实际运行副本数与期望的就绪副本数不一致,存在副本未就绪的情况
5. 守护进程集 (DaemonSet)
- 异常状态:DaemonSet期望调度的Pod数量与实际就绪的Pod数量不一致,存在节点上的Pod未就绪
6. 普通任务 (Job)
- 异常状态:任务执行过程中出现了失败的情况
7. 定时任务 (CronJob)
- 进行中状态:有定时任务正在执行中
8. 自动伸缩 (HPA/VPA)
- 异常状态:水平Pod自动伸缩器的状态条件中存在非”true”状态的条件,表示伸缩功能存在问题
详细说明:
HPA(水平Pod自动伸缩器)的状态条件异常通常表示自动伸缩功能无法正常工作:
AbleToScale(可伸缩)条件
- 当此条件为false时,表示HPA无法获取当前指标或计算目标副本数
- 可能原因:指标API不可用、配置的指标不存在、权限问题等
ScalingActive(伸缩活跃)条件
- 当此条件为false时,表示HPA被禁用或指标收集失败
- 可能原因:HPA被暂停、指标服务器故障、资源指标配置错误等
ScalingLimited(伸缩受限)条件
- 当此条件为true时,表示HPA已达到配置的最大或最小副本数限制
- 可能原因:配置的最小/最大副本数限制、资源配额限制等
9. 容器组 (Pod)
- 未就绪状态:Pod未能达到就绪状态,且Pod并非处于正常完成状态
详细说明:
Pod未就绪意味着它虽然正在运行,但还没有准备好接收流量或提供服务。这种情况通常发生在:
- 容器正在进行初始化
- 就绪探针检查失败
- 依赖的服务或资源尚未可用
- 配置加载过程中
但需要排除Pod已成功执行完毕的情况,这种情况下Pod是正常结束而非异常。
10. 容器 (Container)
- 未就绪状态:容器未能达到就绪状态,且其所在的Pod并非处于正常完成状态
详细说明:
容器未就绪表示容器进程正在运行,但内部服务尚未准备好处理请求。常见场景包括:
- 应用正在启动或初始化
- 数据库连接建立中
- 配置文件加载未完成
- 外部依赖项检查失败
11. 持久卷申领 (PVC)
- 丢失状态:持久卷申领的状态为”Lost”,表示关联的持久卷已丢失
- 等待中状态:持久卷申领的状态为”Pending”,表示正在等待持久卷的绑定
详细说明:
Lost(丢失)状态
- 表示PVC绑定的持久卷由于底层存储问题已不可用
- 可能原因:存储后端故障、存储卷被意外删除、网络连接中断等
- 影响:使用该PVC的Pod将无法访问数据,可能导致应用故障
Pending(等待中)状态
- 表示PVC正在等待合适的持久卷进行绑定
- 可能原因:没有可用的持久卷、存储类配置错误、资源配额不足等
- 注意:短暂的Pending状态是正常的,但长时间Pending需要关注
12. 网络端点 (Endpoint)
- 未就绪状态:端点存在未就绪的地址,或者端点中同时存在就绪和未就绪的地址(表示部分地址未就绪)
作者:叶奕珺 创建时间:2024-08-14 10:06
最后编辑:叶奕珺 更新时间:2026-01-15 14:15
最后编辑:叶奕珺 更新时间:2026-01-15 14:15
